
American lab visibility into AI cyber misuse expires in 3–6 months
The time to invest in societal mitigations is now.

For cyber misuse, the frontier safety paradigm – where labs are the chokepoint – has a shelf life, and it’s about 3–6 months. Open-weight models are approaching the threshold where they’re useful for offensive cyber operations. Once that threshold is crossed, attackers will prefer using open-source models, since even a slightly worse model is worth it if it means not handing evidence of criminal activity to a US company.
This week, Anthropic accused Chinese AI labs Moonshot, DeepSeek, and Minimax of large-scale distillation attacks against Claude. Preventing distillation might be the highest-leverage intervention for slowing down the proliferation of offensive cyber capabilities right now. But even if we figure out how to do that, we should be building defences for a world where open-source models are catching up.

Labs are currently the chokepoint for AI-enabled cyber misuse
Currently, the best models with cyber capabilities come from American labs. They are proving themselves useful to attackers, such as to the hacker who used Claude to steal sensitive Mexican government data, and even to Chinese state-sponsored actors who use Claude for espionage operations.
It’s no longer a question of whether models are useful for attackers; it’s a question of “how useful?” and “how large are the expected damages?”
From a non-proliferation standpoint, the concentration of frontier cyber capabilities in a handful of American labs is structurally useful. When frontier cyber capabilities are held by a handful of companies, the surface area for policy intervention is small: there are only a few entities to regulate, audit, or compel to cooperate with law enforcement. The labs could implement KYC1 requirements, monitor for misuse, and share threat intelligence – and many do so. Whether or not they are currently exercising this power well is a different question, but the structural chokepoint exists, and it makes intervention possible.
In practice, though, the frontier lab safety systems for cyber are arguably not very good. The Mexican government case is revealing. The Bloomberg article quotes OpenAI’s response: “We have banned the accounts used by this adversary and value the outreach from Gambit Security.” OpenAI seems to not have caught the misuse themselves through regular monitoring mechanisms, and instead, they were tipped off by an external security firm to investigate.
Intermediary services complicate monitoring. Even legitimate aggregators like OpenRouter add a layer of indirection – the model provider sees the aggregator’s API key, not the end user’s identity. Illegal reverse proxies, which run on stolen API keys and facilitate a black market for unauthorised access, make monitoring essentially impossible. There’s a case for simply banning2 intermediary API access that isn’t directly KYC’d by the model provider, even if there are legitimate reasons to use aggregators.
But even if labs were significantly better at detecting and disrupting misuse, the structural concentration that makes it possible is eroding.
The open-source capability lag is about 3–6 months
On CyberGym, one of the few public and non-saturated offensive cyber evaluations that I could find, the most capable open-weight model is GLM-5. On this benchmark, the model scores somewhere between Claude Sonnet 4.5 and Claude Opus 4.5. GLM-5 was released on 11 February 2026; Sonnet 4.5 and Opus 4.5 on 29 September 2025 and 24 November 2025, respectively. The approximate lag in cyber capabilities of GLM-5 to the frontier, closed-weight models is about 3 to 5 months.
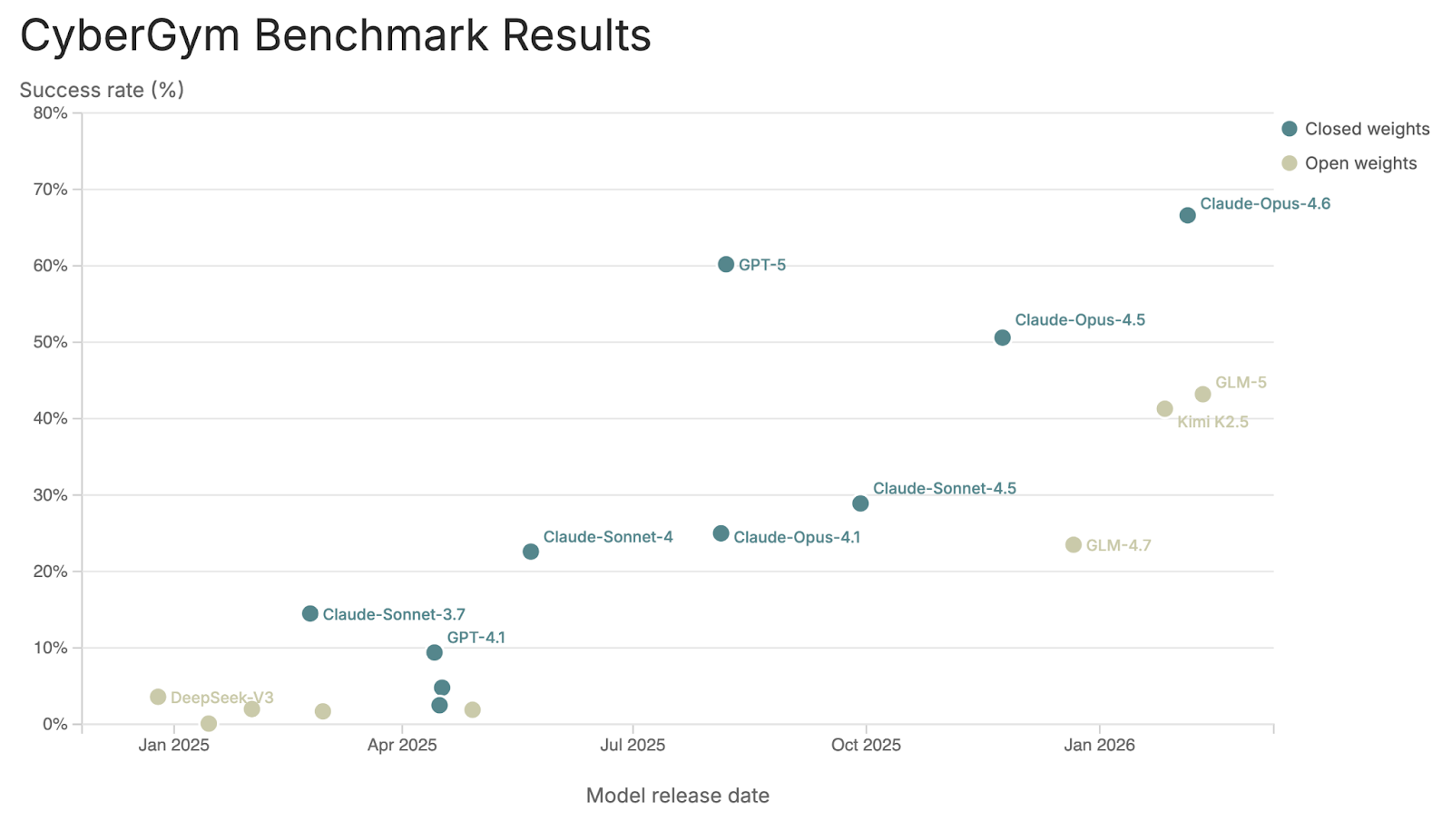
I hesitate to fully trust this assessment because the CyberGym website collects benchmark scores from the model cards of the original publishers. People have speculated that the Chinese open-source model developers make models less useful than their benchmarks would predict because they optimise entirely for the benchmark scores reported in model cards. Chinese models dropped 21% on new AIME 2025 questions versus 10% for Western models, suggesting weaker generalisation to unseen data; and Kimi K2.5’s reported benchmark scores use test-time inflation techniques that don’t reflect what you’d get from a single inference pass.
A better assessment would be done using non-lab, independently run evals. The Epoch Capabilities Index is a composite evaluation, but it does include in-house run evaluations, including their own Frontier Math eval. Scores for GLM-5 are not yet available, but the ECI score of Kimi 2.5 (released 27 January 2026) is 148, putting it again between Sonnet 4.5 and Opus 4.5 and indicating a lag of 3–4.5 months.
GPT-5 was somewhat of an outlier on the frontier trend, and I’m not totally sure what to do with it; GLM-5 came out about 6 months after GPT-5. On the whole, the current capabilities lag seems to be about 3–6 months. The lag matters because there’s a capability threshold, somewhere around the late-2025 frontier levels, where models go from ‘somewhat helpful for cyber’ to ‘operationally useful.’ Open-weight models are also approaching this threshold.
Once open source is good enough, attackers won’t need American labs
Something happened in December 2025 that even I, someone who primarily writes reports and blog posts for a living, noticed. Andrej Karpathy explains the step change:
“There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.”
I don’t have first-hand evidence, but it seems that a similar step change happened in cyber capabilities as well. In mid-January, Sean Heelan published an excellent blog post on using then-frontier models3 to create exploits. Cybersecurity professionals I’ve spoken with say the techniques demonstrated in Heelan’s post would challenge even seasoned practitioners.4 Other cybersecurity professionals tell me that they experienced a shift in how much work agents could do in the past few months as well.
Once open-weight models cross the same threshold, attackers will switch for two reasons: operational security and operational reliability. Neither of these depend on how well the labs enforce their safety policies.
A rational attacker has to assume that every API call to a US lab could generate a forensic record on servers that can be subpoenaed by Western law enforcement. Separately, cybercriminal operations are often surprisingly industrialised, and building critical infrastructure on top of a service that can revoke your access at any time is an unacceptable operational dependency. Even if open-weight models are behind by a few months, the gains on both fronts will be worth the capability trade-off.
If the 3–6 month lag holds and the benchmark scores are real, then open-weight models are right at or just below the “actually useful for cyber” threshold now, and will clearly cross it within the next few months. I’m uncertain as to whether it’s already happened because Chinese companies are known for eval gaming, and also, I don’t know anyone actually using these models. Absence of practitioner evidence isn’t proof it’s not happening: I just don’t talk to a lot of people who wouldn’t just use Codex or Claude.
There are relatively easy paths for evading Western visibility for attackers by using Chinese APIs. Attackers could steal credit card information to pay for the Moonshot or Z.ai API directly; or just use stolen API keys. Moonshot and Z.ai are required to cooperate with Chinese intelligence, but they have no meaningful incentive or mechanism to report abuse to Western law enforcement. For non-Chinese threat actors (e.g. Russian ransomware groups, Southeast Asian fraud operations), this makes Chinese API access a very low-risk avenue. Chinese state-sponsored actors, meanwhile, presumably don’t need stolen credit cards at all. Sysdig reported that operators who run illegal reverse proxies on stolen API keys added DeepSeek models within days of release, suggesting this shift is already underway.
For more sophisticated actors, fully private on-prem deployment is also within reach. Deploying Kimi 2.5 on-prem requires significant capex: roughly $200–500K all in5, depending on configuration, for usable agentic coding throughput. But the implicit assumption that this hardware is hard for cybercriminals to get doesn’t hold up. The World Cybercrime Index ranks the top six sources of cybercrime as Russia, Ukraine, China, the US, Nigeria, and Romania. Of these, three – Ukraine, the US, and Romania – face zero export restrictions on GPU hardware. Russia and China, the two countries most relevant to US national security, are the only top-six sources that face genuine hardware access constraints, and even there, there is a prolific grey market.
On-prem doesn’t even have to be the likely path to lose visibility into attacker usage. Between Chinese APIs, non-KYC cloud providers, and compromised infrastructure, there are many ways to run open-weight models outside Western visibility. The appetite for doing so already exists. Mandiant reports that “there is an enduring market for AI services specifically designed to support malicious activity” and I see no reason why this market will go away. One such service, Xanthorox, advertises itself as running “security on our dedicated servers” and “not sharing data with third-party corporations,” showing that this is clearly a desirable quality for attackers6.
Distillation might be accelerating the proliferation of offensive cyber capabilities
Anthropic recently accused Moonshot, the makers of Kimi, as well as DeepSeek and Minimax, of illicitly extracting Claude’s capabilities to train their own models. It was a large operation: the Chinese labs “generated over 16 million exchanges with Claude through approximately 24,000 fraudulent accounts.” Google Threat Intelligence also wrote in the past few weeks of a distillation attack campaign against Gemini, identifying “over 100,000 prompts.”
Moonshot is the same company that makes Kimi 2.5, the frontier-on-benchmarks-model, whose API I previously described above as a low-risk access point for attackers wanting frontier capabilities without Western law enforcement oversight. Moonshot distills from Claude and makes these capabilities freely available to adversaries and attackers. The case for preventing distillation is larger than just protecting corporate IP. If distillation is what’s keeping the open-weight lag to just 3–6 months, then anti-distillation efforts are also a cybersecurity misuse intervention. Mitigating distillation directly protects the window in which labs can still see and respond to misuse.
To what extent are Kimi and GLM’s cyber capabilities due to distillation? It’s hard to say, but if these models are only 3–6 months behind because they’re collecting data from Anthropic, OpenAI, and Google DeepMind and training on it, then making distillation harder is one of the highest-leverage interventions available right now.
Plan for resilience, not for control
Even if we can fully protect against distillation attacks, though, it won’t fully solve the problem. The Chinese state-sponsored espionage campaign that Anthropic disrupted in September 2025 was conducted using Claude Code, which at the time ran on Opus 4.1. Current open-weight models already score above Opus 4.1 on capability benchmarks. The capabilities that enabled the first documented autonomous cyber espionage operation are, in all likelihood, already available in the near-frontier open-weight models. There’s also probably an elicitation overhang: not every attacker has yet discovered the best prompting strategies and tool-use patterns for offensive cyber, but they will.
We have to reckon with the fact that we now live in a world where attackers have access to advanced cyber-attack capabilities. There is no putting the cat back in the bag. Even if we expect no further progress from open or closed models, we should expect future harm as attackers learn how to best apply what’s already available.
The lab-based safety paradigm buys time, but not much, and anti-distillation efforts can extend it but can’t preserve it indefinitely. The priority now should be investing in defences that work regardless of where the model lives – hardening the institutions most likely to be targeted, building AI-powered defensive tooling designed for real operational constraints, and developing detection and attribution capabilities that don’t depend on visibility into model providers.
In my next blog post, I’ll describe what a serious investment agenda along these lines would look like.
Thank you to Adam Swanda, Jake Steckler, Amelia Michael, Aidan Homewood, Matthew van der Merwe, and Alan Chan for feedback on this piece.
Know Your Customer – requiring users to identify themselves, e.g. by creating an account, providing a credit card, or verifying identity.
I don’t love that my best policy analogy here is an authoritarian government, but: China banned Bitcoin in 2021, on the basis of the same reasoning: legitimate use cases exist, sure, but the crime-enabling downside isn’t worth it.
Opus 4.5 and GPT-5.2
Shout out to Heron Security for hosting a delegation of 14 cybersecurity professionals who participated in my workshop on AI cyber capabilities.
Running Kimi requires 4–8 high-end NVIDIA GPUs (e.g. H100, B200), with total hardware costs ranging from roughly $120,000 to $300,000 depending on configuration. Individual B200 GPUs sell for $30,000–$40,000 each (Epoch AI, Dec 2025; Jan 2026); an 8-GPU H100 server runs ~$190,000 at hyperscaler pricing or ~$280,000 at retail (Epoch AI, Jan 2026). Assuming GPU hardware is roughly 60% of total datacenter operating costs, total deployment costs are approximately $200,000–$500,000. This hardware setup would support roughly 10–20 concurrent agentic sessions.
This Xanthorox is a bit of a meme because Mandiant reports that Xanthorox is not a custom AI at all but rather using stolen API keys for frontier models and routing traffic to them; but I expect more advanced attackers to do better and actually maintain proper opsec.